Narrow AI vs. Artificial General Intelligence
Unit 1: Foundations of Artificial Intelligence — Section 1.3
After tracing AI’s history, let’s assess where the field actually stands. AI has achieved remarkable success in specific domains while still struggling with tasks a four-year-old finds trivial. Understanding this uneven landscape — and the distinction between what we have and what remains theoretical — is fundamental for anyone working with AI systems.
What AI Does Exceptionally Well
Game Playing
AI has conquered games that were once considered pinnacles of human intelligence.
Three milestone achievements in game-playing AI:
Chess (1997) — Deep Blue vs. Kasparov: IBM’s Deep Blue defeated world champion Garry Kasparov using brute-force search, evaluating millions of positions per second. Chess had been a benchmark problem since the 1950s; it took 40 years longer than predicted.
Go (2016) — AlphaGo vs. Lee Sedol: Go’s complexity (more legal positions than atoms in the observable universe) was thought to require human intuition. AlphaGo combined deep neural networks with Monte Carlo tree search to defeat the world’s top players. Unlike Deep Blue’s brute force, AlphaGo learned to evaluate board positions in a way that resembles human pattern recognition.
Poker (2017) — Libratus vs. Professionals: Texas Hold’em requires managing hidden information and strategic deception. Carnegie Mellon’s Libratus mastered bluffing and beat the world’s top professionals, demonstrating that AI could handle imperfect information games.
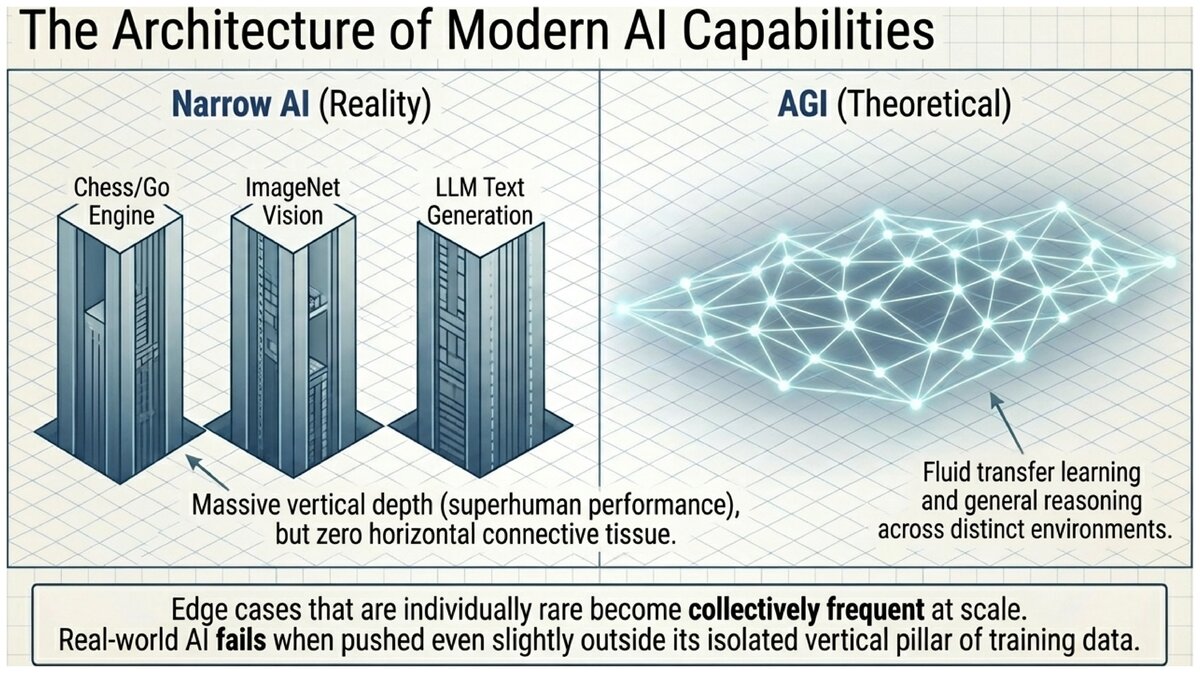
Here is the critical observation: all three of these systems are completely specialized. AlphaGo cannot play chess. Deep Blue cannot play Go. A poker AI cannot write a sentence.
- Narrow AI (Artificial Narrow Intelligence, ANI)
-
AI systems designed and optimized for a specific task or narrow domain. All currently deployed AI — including ChatGPT, image recognition systems, and self-driving vehicles — is narrow AI. These systems may dramatically outperform humans within their domain while being entirely incapable outside it.
Natural Language Processing
Language AI has progressed dramatically, especially since the introduction of Transformer architectures in 2017.
-
Machine translation can handle over 100 languages with quality suitable for many practical purposes.
-
Speech recognition achieves near-human accuracy for clear, standard speech in high-resource languages.
-
Large language models such as GPT-4 generate fluent text, summarize documents, write and debug code, and answer questions across a remarkable range of topics.
The important caveat: These systems do not understand language the way humans do. They excel at pattern completion but can produce confidently stated falsehoods (called hallucinations), fail on novel logical problems that require genuine reasoning, and lack consistent long-term knowledge.
Computer Vision
Image recognition has reached and sometimes exceeded human performance on standard benchmarks.
-
Object recognition on the ImageNet benchmark: modern systems exceed 98% accuracy; humans score approximately 95%.
-
Medical imaging AI detects certain cancers from scans as accurately as specialist radiologists.
-
Image generation systems can synthesize photorealistic images from text descriptions.
Scientific Applications
Some of AI’s most significant recent contributions have been in science rather than consumer products.
DeepMind’s AlphaFold (2020-2021) predicted the three-dimensional shapes of proteins from their amino acid sequences with unprecedented accuracy — solving a 50-year-old challenge in structural biology and opening new possibilities for drug discovery.
What AI Still Cannot Do Well
AI’s limitations are as important to understand as its capabilities. The gap between what AI can do within a trained domain and what humans can do in general is enormous.
Common-sense reasoning: Humans know that wet things dry over time, that you cannot fit a car in a shoebox, that glasses break when dropped. This everyday knowledge, learned through embodied experience, is extraordinarily difficult to encode in AI systems. A language model may "know" that wet things dry but cannot reliably use that knowledge correctly in a novel situation.
Few-shot learning: Humans can learn a new concept from a single example. AI typically requires thousands or millions of labeled examples to reach good performance. Though recent large language models show improved few-shot performance, they still fall far short of human generalization.
Causal reasoning: AI systems are excellent at finding correlations in data but struggle to identify true cause-and-effect relationships. Knowing that two things are correlated is not the same as knowing that one causes the other — a distinction critical for medical research, policy analysis, and safety.
Explainability: Deep learning models are often called "black boxes" — even their designers cannot fully articulate why a specific input produced a specific output. This opacity creates serious problems for high-stakes applications such as medical diagnosis and criminal justice.
Physical manipulation: Robotics lags far behind software AI. Tasks that require dexterous manipulation of physical objects in unstructured environments — such as loading a dishwasher or making a sandwich — remain unsolved.
The Narrow vs. General AI Distinction
| Narrow AI (ANI) | Artificial General Intelligence (AGI) |
|---|---|
Designed for a specific task or domain |
Hypothetical AI with human-level performance across all intellectual domains |
All current AI systems fit here |
Could learn any task a human can, transfer knowledge between domains, and reason generally |
Can dramatically outperform humans within its domain |
Would not need task-specific training for each new problem |
Inflexible outside its training domain |
Does not exist; no one knows how to build it |
What we actually have |
What we imagine in science fiction |
- Artificial General Intelligence (AGI)
-
A hypothetical AI system with the ability to understand, learn, and apply knowledge across any intellectual domain at least as well as a human. No AGI system exists; the term describes a research goal whose difficulty and timeline remain deeply contested.
- Superintelligence
-
A hypothetical AI system that surpasses human cognitive performance across all domains. Proposed by philosopher Nick Bostrom, superintelligence remains speculative — a concept in the philosophy of AI rather than a near-term technical prospect.
Managing the Hype
A crucial skill for anyone working with AI is calibrating claims against evidence. AI capabilities are remarkable in certain narrow domains and severely limited in others. Media coverage tends to highlight dramatic successes (AlphaGo defeats a Go champion!) while burying quiet failures (the same system cannot generalize to chess).
When you hear claims about what AI "can" or "will soon be able to" do, ask: How narrow is the task? How much labeled training data was required? Does it generalize outside its training distribution?
The self-driving car timeline: In 2015, several automotive executives and AI researchers predicted fully autonomous vehicles on public roads within five years. As of 2026, limited autonomous operation in geofenced areas (specific cities, highway-only, etc.) exists, but fully general autonomous driving in all conditions remains unsolved.
This is not a failure of intelligence — it reflects the genuine difficulty of handling the long tail of rare, unpredictable situations that occur in the real world. Edge cases that are individually rare become collectively frequent at scale.
How to evaluate an AI capability claim:
-
Identify the specific task. Is it narrow (image classification on a benchmark) or general (understanding images in novel contexts)?
-
Ask about training data. How much, and how similar is it to the deployment environment?
-
Look for independent evaluation. Did researchers other than the system’s developers test it?
-
Check for brittleness. Does small variation in inputs cause large variation in outputs?
-
Ask who is harmed when it fails. High-stakes applications (medical, legal, safety-critical) need much higher reliability than entertainment applications.
Looking at what AI can and cannot do, what pattern do you notice? Why do you think some tasks are dramatically easier for AI than others?
Consider: image classification, playing chess, writing poetry, understanding a joke that requires cultural context, loading a dishwasher, and making a moral judgment. Rank these from most to least tractable for current AI. What features of a task seem to predict whether AI will handle it well?
Test your understanding of AI capabilities and the narrow vs. general AI distinction.
Understanding what AI can and cannot do sets the stage for exploring where AI is actually deployed in society today — and what that means for individuals, organizations, and communities.
Original content for CSC 114: Artificial Intelligence I, Central Piedmont Community College.
This work is licensed under CC BY-SA 4.0.