Learning Agents
Unit 2: Intelligent Agents — Section 2.5
Every agent architecture we have studied so far shares a significant limitation: the rules, models, goals, and utility functions are fixed at design time. The designer must anticipate every important situation and encode the correct response. For simple problems, this works. For the real world, it fails — the world is too varied, too unpredictable, and too complex for any human designer to fully specify in advance.
Learning agents break this constraint. They start with basic capabilities and improve over time, adapting to environments that change in unexpected ways and discovering patterns their designers never anticipated.
The Learning Agent Architecture
A learning agent has four components that work together in a continuous feedback cycle:
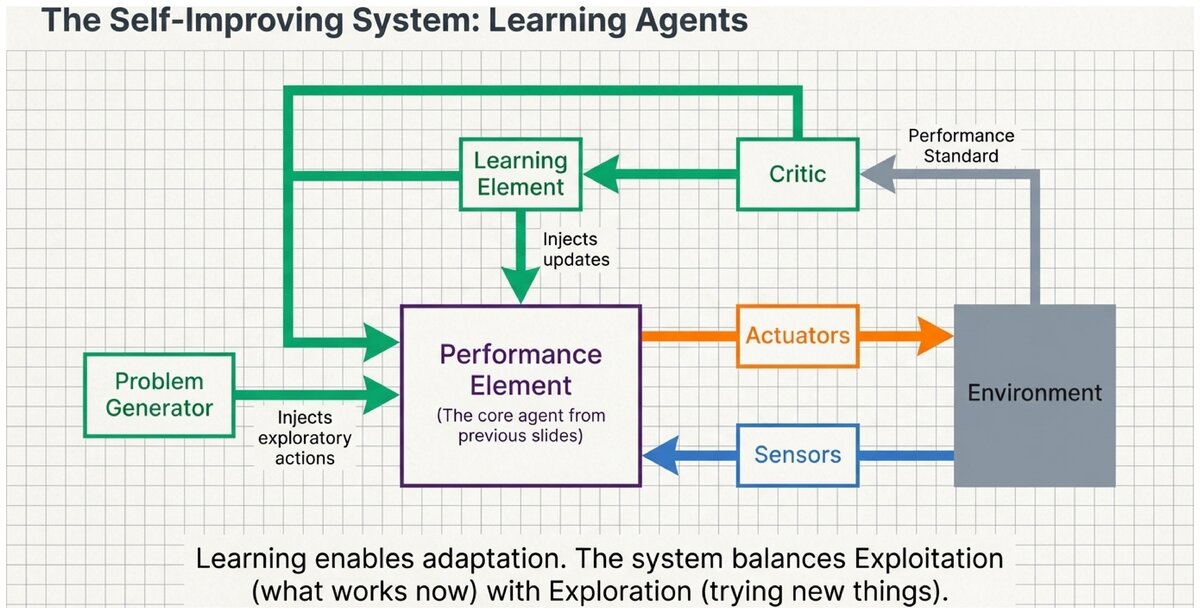
- Performance Element
-
The component that selects actions — the "current agent." It can be any architecture: simple reflex, model-based, goal-based, or utility-based. The learning process modifies this component over time to improve its performance.
- Critic
-
The component that evaluates how well the agent is performing by comparing its behavior against a fixed performance standard. The critic provides feedback to the learning element by observing outcomes and assigning rewards, penalties, or corrections. The critic is external to the agent’s decision-making loop — it evaluates, not decides.
- Learning Element
-
The component that makes improvements to the performance element based on feedback from the critic. It identifies what changes to the agent’s knowledge, rules, or parameters would have produced better performance, and applies those changes.
- Problem Generator
-
The component that suggests exploratory actions — actions the agent has not tried much, or novel situations worth investigating. It balances exploitation (doing what works now) against exploration (trying new things that might work better in the long run).
How the Components Interact
The Learning Feedback Cycle:
-
Performance Element selects an action based on its current knowledge and the current percept
-
The agent acts — the action changes the environment
-
Critic observes the outcome and evaluates it against the performance standard
-
Learning Element receives the critic’s feedback and modifies the performance element (adjusting rules, weights, models, or parameters)
-
Problem Generator occasionally overrides the performance element to suggest exploratory actions that expand the agent’s experience
-
Repeat — the agent’s performance element is now slightly better (or at least more informed) than before
A Detailed Example: Self-Driving Car Learns to Park
Learning to Park Through Experience
Initial Performance Element: A basic parking strategy — align with the space, back in slowly, adjust based on distance sensors.
Critic: Evaluates each parking attempt:
-
Parked within lines, no contact: +10 points
-
Parked but crooked: +5 points
-
Touched curb: -5 points
-
Contact with another vehicle: -20 points
After 50 attempts — Learning Element observes: "In narrow spaces (width < 1.2× car width), the current turn timing causes wheel-scuffing on curbs." → Update: "In narrow spaces, begin turn arc 0.5 meters earlier."
After 200 attempts — Performance has improved from 60% clean parks to 88%.
Problem Generator suggests: "Most learning has occurred in standard-width spaces. Try some extra-narrow and extra-wide spaces to learn those edge cases. Also: you always back in — try pull-forward parking to discover whether it is ever more efficient."
Result: Over time, the agent develops parking skills more nuanced than any human designer could have pre-specified as rules.
Three Modes of Learning
The learning agent architecture applies to all three major types of machine learning. What differs is the form of feedback the critic provides:
| Learning Type | Feedback Provided | Example |
|---|---|---|
Supervised Learning |
Correct answers are provided for each input (labeled training data) |
Email spam filter trained on thousands of emails labeled "spam" or "not spam" |
Unsupervised Learning |
No labels are provided; the agent must find patterns on its own |
Customer segmentation — find natural groupings in customer behavior data without pre-defined categories |
Reinforcement Learning |
Rewards and penalties are given for actions over time, but no correct action is specified directly |
Game-playing AI receives +1 for winning, -1 for losing, and 0 for draws; it must discover which moves lead to wins |
The learning agent architecture is a general framework that encompasses all three modes. The difference is not in the structure of the agent but in how the critic communicates with the learning element:
-
Supervised: critic says "the correct answer was X"
-
Unsupervised: critic says nothing (agent discovers structure independently)
-
Reinforcement: critic says "that sequence of actions earned +5 reward"
The Exploration-Exploitation Trade-Off
The problem generator exists because of a fundamental tension in learning:
Exploitation means using what you already know to get good results right now. Exploration means trying new things to gain information that might lead to better results in the future.
A pure exploitation agent never discovers better strategies it has not yet tried. A pure exploration agent never applies what it has learned — it keeps trying random things.
Effective learning requires balancing both.
Netflix Recommendation System
A Netflix recommendation agent that only exploits would only recommend shows similar to what you have already rated highly. You would never discover new genres you might enjoy.
A Netflix recommendation agent that only explores would show you random, unrelated content to "see what sticks." You would be frustrated by constant irrelevant recommendations.
The actual system explores occasionally — recommending something outside your apparent preferences — to discover new taste dimensions. The problem generator in this system might say: "This user has never rated a documentary. Recommend one high-rated documentary to learn their preference."
Why Learning Matters: Four Key Insights
1. Designers cannot anticipate everything. Instead of encoding rules for every situation, a learning agent discovers appropriate responses through experience. The designer provides the learning mechanism and performance standard; the agent fills in the details.
2. Learning agents adapt to changing environments. If spam techniques evolve, a fixed spam filter fails; a learning spam filter adapts. If traffic patterns change, a fixed route-planner gives outdated advice; a learning route-planner updates its model.
3. Learning agents can exceed their designers. AlphaGo, trained via reinforcement learning, discovered Go strategies that professional human players described as "alien" and "beautiful" — strategies no human programmer had conceived.
4. Learning during deployment carries risks. During learning, an agent may try suboptimal or even dangerous actions. This is acceptable in a video game or recommendation system; it is not acceptable in a medical device or autonomous vehicle. Safe learning methods (offline learning, simulation, sandboxed environments) are an active area of research.
Real-World Learning Agents
Spam Filter (Supervised Learning)
-
Performance Element: Current classification model
-
Critic: User marks emails "This is spam" or "Not spam"
-
Learning Element: Updates Bayesian or neural model weights based on corrections
-
Problem Generator: Periodically routes borderline emails to users for labeling (active learning)
Recommendation System (Reinforcement Learning)
-
Performance Element: Current recommendation policy (what to show next)
-
Critic: Watches whether users watch, skip, or click away from recommendations
-
Learning Element: Adjusts recommendation weights based on engagement signals
-
Problem Generator: Occasionally recommends outside the user’s apparent taste profile to learn new dimensions
Connection to Future Units
Learning agents are the conceptual bridge between the rule-based and architecture-focused systems of Units 2–6 and the probabilistic and machine learning systems of Units 7–8.
When you encounter neural networks, Bayesian learning, and reinforcement learning later in the course, you will find that all of them are implementations of the learning element — they are different answers to the question: "Given the critic’s feedback, how do we update the performance element?"
Consider a learning agent designed to recommend news articles to users.
-
What would the performance element look like initially (before any learning)?
-
How would the critic evaluate whether a recommendation was good?
-
What risk does the problem generator introduce in this context?
-
How might a poorly specified performance standard lead the learning element to optimize for the wrong thing? (Hint: think about the difference between "maximizing clicks" and "maximizing reader satisfaction.")
Test Your Understanding
Identify the components of learning agents and distinguish learning modes.
Based on the UC Berkeley CS 188 Online Textbook by Nikhil Sharma, Josh Hug, Jacky Liang, and Henry Zhu, licensed under CC BY-SA 4.0.
This work is licensed under CC BY-SA 4.0.