Bayesian Reasoning in Practice
Unit 7: Probability and Uncertainty in AI — Section 7.4
A positive COVID test. An email flagged as suspicious. A smoke detector alarm. In every case, we observe evidence and want to know what it tells us about something we cannot directly see. Bayes' theorem is the mathematical formula for answering precisely that question. It is arguably the single most important equation in artificial intelligence.
See how a Bayesian network represents probabilistic diagnosis in action.
The Core Insight: Inverting Probability
Medical researchers measure P(Positive Test | Disease) — the probability that a test comes back positive in patients who actually have the disease. This is called the test sensitivity and it is straightforward to measure in a clinical trial.
But what a patient wants to know is P(Disease | Positive Test) — given that I tested positive, how likely am I actually to be sick?
These two quantities look similar but are completely different numbers. Bayes' theorem is the formula that connects them, allowing us to compute one from the other.
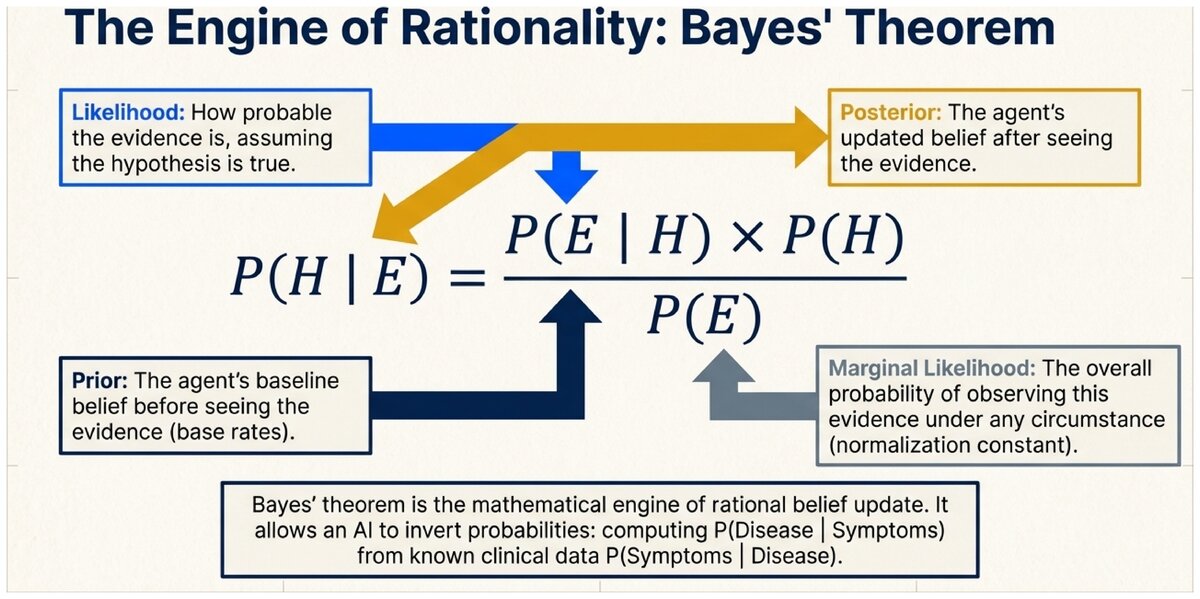
Bayes' Theorem
P(H | E) = [P(E | H) × P(H)] / P(E)
Where:
-
H = Hypothesis (what we want to know about)
-
E = Evidence (what we observed)
-
P(H | E) = Posterior probability: belief after seeing evidence
-
P(E | H) = Likelihood: how probable the evidence would be if H were true
-
P(H) = Prior probability: belief before seeing evidence
-
P(E) = Marginal likelihood: overall probability of observing this evidence
The term P(E) is computed using the law of total probability from Section 7.2:
Marginal Likelihood (two-hypothesis case)
P(E) = P(E | H) × P(H) + P(E | ¬H) × P(¬H)
The Mammogram Paradox
This classic example illustrates why the posterior probability often surprises people — and why Bayesian reasoning is so essential in medicine.
Scenario: A woman receives a positive mammogram result. What is the probability she actually has breast cancer?
Given information:
-
P(Cancer) = 0.01 — 1% of women in this age group have breast cancer
-
P(Positive | Cancer) = 0.90 — the test detects 90% of actual cancers (sensitivity)
-
P(Positive | No Cancer) = 0.09 — 9% of cancer-free women test positive (false positive rate)
Step 1: Compute P(Positive) using the law of total probability
P(Positive) = P(Positive | Cancer) × P(Cancer)
+ P(Positive | No Cancer) × P(No Cancer)
= 0.90 × 0.01 + 0.09 × 0.99
= 0.0090 + 0.0891
= 0.0981
Step 2: Apply Bayes' theorem
P(Cancer | Positive) = P(Positive | Cancer) × P(Cancer) / P(Positive)
= 0.90 × 0.01 / 0.0981
= 0.0090 / 0.0981
≈ 0.092
Result: About 9%
Most people guess 80-90% when first presented with this problem. The actual answer is only 9%.
Why? Because cancer is rare (1%), the vast majority of positive tests are false positives. Out of 1,000 women: approximately 9 true positives (cancer + positive test), and approximately 89 false positives (no cancer + positive test). So P(Cancer | Positive) = 9 / (9 + 89) ≈ 9%.
The mammogram paradox has profound implications for public health policy. If a test with 90% sensitivity and 9% false positive rate is applied to the general population, about 91% of positive results will be false positives.
How should this affect: - How doctors communicate test results to patients? - Which populations are targeted for routine screening? - How we design and evaluate diagnostic tests?
This is not a theoretical concern: multiple medical organizations have revised screening recommendations based on exactly this kind of Bayesian analysis.
Bayesian Updating: Learning from Multiple Pieces of Evidence
One of Bayes' theorem’s most powerful properties is that it can be applied sequentially. After updating beliefs based on one piece of evidence, the posterior becomes the new prior for the next piece of evidence.
Sequential Bayesian Updating
-
Start with prior P(H) based on background knowledge.
-
Observe evidence E₁. Compute posterior₁ = P(H | E₁) using Bayes' theorem.
-
Set prior₂ = posterior₁.
-
Observe evidence E₂. Compute posterior₂ = P(H | E₁, E₂) using Bayes' theorem.
-
Repeat for each new piece of evidence.
Each update incorporates all previous evidence while adding only the new information.
Spam Filter: Sequential Updating
Prior: P(Spam) = 0.30 (30% of all email is spam)
Evidence 1: Subject line contains "FREE"
-
P("FREE" | Spam) = 0.80
-
P("FREE" | Ham) = 0.05
P(Spam | "FREE") = (0.80 × 0.30) / (0.80 × 0.30 + 0.05 × 0.70)
= 0.240 / (0.240 + 0.035)
= 0.240 / 0.275
≈ 0.87
After "FREE": P(Spam) updated to 0.87.
Evidence 2: Email also contains "URGENT"
-
P("URGENT" | Spam) = 0.65
-
P("URGENT" | Ham) = 0.02
New prior = 0.87, New P(Ham) = 0.13.
P(Spam | "FREE", "URGENT") = (0.65 × 0.87) / (0.65 × 0.87 + 0.02 × 0.13)
= 0.5655 / (0.5655 + 0.0026)
≈ 0.996
After two suspicious words: P(Spam) ≈ 99.6%. This email would definitely be filtered.
Bayesian Reasoning in Medical Diagnosis
Medical diagnosis is the quintessential Bayesian application because:
-
Diseases have known base rates (priors) from epidemiological data.
-
Tests have known sensitivity and specificity (likelihoods) from clinical trials.
-
Doctors must rank hypotheses and communicate uncertainty to patients.
-
The stakes of misclassification are high (false negatives = missed disease; false positives = unnecessary treatment).
Multi-Symptom Diagnosis
A patient presents with fever (F), cough ©, and muscle aches (A).
Three candidate diseases: Influenza (I), Common Cold (Co), COVID-19 (Co19).
Priors in this season:
-
P(Influenza) = 0.20
-
P(Cold) = 0.45
-
P(COVID-19) = 0.10
-
P(Other) = 0.25
Likelihoods for the symptom pattern (F ∧ C ∧ A):
-
P(F ∧ C ∧ A | Influenza) = 0.70
-
P(F ∧ C ∧ A | Cold) = 0.15
-
P(F ∧ C ∧ A | COVID-19) = 0.60
-
P(F ∧ C ∧ A | Other) = 0.10
Unnormalized posteriors (numerators of Bayes' theorem):
Influenza: 0.70 × 0.20 = 0.140 Cold: 0.15 × 0.45 = 0.068 COVID-19: 0.60 × 0.10 = 0.060 Other: 0.10 × 0.25 = 0.025 Sum (P(evidence)) = 0.293
Normalized posteriors:
P(Influenza | symptoms) = 0.140 / 0.293 ≈ 0.48 P(Cold | symptoms) = 0.068 / 0.293 ≈ 0.23 P(COVID-19 | symptoms) = 0.060 / 0.293 ≈ 0.20 P(Other | symptoms) = 0.025 / 0.293 ≈ 0.09
The system recommends testing for influenza (most likely at 48%) while keeping COVID-19 on the differential (20%).
Key Terms Consolidated
- Prior Probability
-
P(H) — the probability of a hypothesis before observing evidence. Represents background knowledge, historical frequency, or domain expertise.
- Likelihood
-
P(E | H) — how probable the observed evidence would be if the hypothesis H were true. Measures how well the hypothesis "explains" the evidence.
- Posterior Probability
-
P(H | E) — the probability of a hypothesis after incorporating the observed evidence. Always computed from prior × likelihood, then normalized.
- Evidence (Marginal Likelihood)
-
P(E) — the overall probability of observing the evidence across all hypotheses. Acts as a normalization constant so posterior probabilities sum to 1.
Bayes' theorem is the engine of rational belief update. Given a prior belief and the likelihood of evidence under that belief, Bayes' theorem computes exactly how much to revise the belief upon observing evidence. Every spam filter, medical diagnostic system, and Bayesian AI planner uses this equation at its core.
Apply Bayes' theorem to a new scenario.
Based on the UC Berkeley CS 188 Online Textbook by Nikhil Sharma, Josh Hug, Jacky Liang, and Henry Zhu, licensed under CC BY-SA 4.0.
This work is licensed under CC BY-SA 4.0.